TCP-IP крупным планом
D.1 Количество сетей в сети NSFNET.
Рисунок D.1 Количество сетей в сети NSFNET.
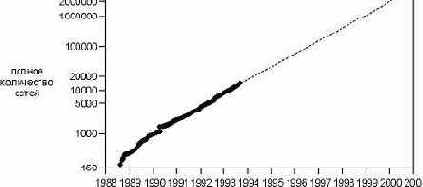
Пунктирная линия примерно показывает максимальное количество сетей, которое будет достигнуто к 2000 году, если продолжится экспоненциальный рост количества сетей.
Глава 3
- Нет, любой адрес класса сети с идентификатором, начинающимся со 127, имеет право существовать, однако большинство систем использует 127.0.0.1.
- kpno имеет пять интерфейсов: три канала точка-точка и два Ethernetа. R10 имеет четыре интерфейса Ethernet. gateway имеет три интерфейса: два канала точка-точка и один Ethernet. И netb имеет один интерфейс Ethernet и два канала точка-точка.
- Нет никакой разницы: оба имеют маски подсети 255.255.255.0, как адреса класса С, которые не поделены на подсети.
- Можно. Это называется непересекающиеся сетевые маски, так как 16 бит, выделенные под маску подсети, не пересекаются. RFC, однако, рекомендует не использовать непересекающиеся сетевые маски.
- Так сложилось исторически. Значение получилось как 1024 + 512 при этом напечатанные значения MTU включают все требуемые заголовки. Solaris 2.2 устанавливает MTU для loopback интерфейса равный 8232 (8192 + 40), что вмещает в себя 8192 байта пользовательских данных вместе с обычным 20-байтовым IP заголовком и 20-байтовым TCP заголовком.
- Во-первых, с датаграммами значительно легче работать маршрутизаторам. Во-вторых, на основе датаграмм могут быть основаны и ненадежные (UDP) и надежные (TCP) транспортные уровни. В-третьих, датаграммы представляют собой минимальное представление сетевого уровня, что позволяет использовать разнообразные канальные уровни.
Глава 4
- Исполнение команды rsh устанавливает TCP соединение с удаленным хостом. При этом начинается обмен IP датаграммами между двумя хостами. При этом требуется, чтобы на удаленном хосте была запись в ARP кэше. Даже если ARP кэш был пуст перед исполнением команды rsh, можно гарантировать, что запись для нашего хоста в ARP кэше появится, перед тем как сервер rsh исполнит команду arp.
- Убедитесь, что ваш хост не имеет записи в своем ARP кэше для какого-либо другого хоста в той же Ethernet сети, скажем foo. Убедитесь, что foo посылает "беспричинный" ARP запрос при загрузке. Это можно сделать, запустив tcpdump на другом хосте, когда загружается foo. Затем погасите хост foo и внесите неверный пункт в ARP кэш на вашей системе для foo. Используйте команду arp и не забудьте указать опцию temp. Загрузите foo, и когда он загрузился, посмотрите ваш ARP кэш на предмет того, была ли исправлена неверная запись.
- Прочитайте раздел 2.3.2.2 в требованиях к хостам Host Requirements RFC и раздел "Взаимодействие между UDP и ARP" главы 11 этой книги.
- Допустим, у клиента существовала полная ARP запись для сервера, когда сервер был выключен. Если мы будем продолжать попытки подсоединиться к серверу (выключенному), тайм-аут ARP будет продлен еще на 20 минут. Когда сервер окончательно перезагрузится с новым аппаратным адресом, и если он не разошлет "беспричинный" ARP, старая неверная ARP запись будет все еще останется у клиента. У нас не будет возможности подсоединиться к серверу на его новый аппаратный адрес до тех пор, пока мы вручную не удалим запись в ARP кэше или прекратим на 20 минут попытки достучаться до сервера.
Глава 5
- Разные типы фреймов это не абсолютное требование, так как поле op на рисунке 4.3 имеет различные значения для всех четырех операций (ARP запрос, ARP отклик, RARP запрос и RARP отклик). Однако отличить реализацию RARP сервера от ARP сервера, находящегося в ядре, значительно легче с разными полями в поле типа фрейма.
- Каждый RARP сервер может осуществить маленькую задержку на случайный момент времени, перед тем как отправить ответ. В качестве усовершенствования, один RARP сервер может быть назначен как первичный, а все остальные как вторичные. Первичный сервер может отвечать без задержки, а вторичные со случайными задержками. Еще одно усовершенствование. В случае использования первичных и вторичных серверов, вторичные сервера могут быть запрограммированы таким образом, чтобы отвечать только на повторные запросы, принятые за короткие промежутки времени. При этом подразумевается, что причина появления повторных запросов заключается в том, что первичный сервер выключен.
Глава 6
- Если бы на одном локальном кабеле находилась сотня хостов, каждый попробовал бы послать ICMP ошибку о недоступности порта примерно в одно и то же время. Это привело бы к коллизиям (если используется Ethernet), при этом сеть станет практически бесполезной в течение секунды или двух.
- В этом случае "следует".
- ICMP ошибка всегда отправляется с TOS равным 0, как показано на рисунке 3.2. ICMP запрос может быть отправлен с любым TOS, но соответствующий отклик должен быть отправлен с тем же самым TOS.
- Команда netstat -s обычно используется для того, чтобы посмотреть статистику по протоколам. На хосте SunOS 4.1.1 (gemini), который получил 48 миллионов IP датаграмм, ICMP статистика следующая:
Output histogram: echo reply: 1757 destination unreachable: 700 time stamp reply: 1 Input histogram: echo reply: 211 destination unreachable: 3071 source quench: 249 routing redirect: 2789 echo: 1757 #10: 21 time exceeded: 56 time stamp: 1
21 входное сообщение с типом 10 - это требования к маршрутизатору, которые не поддерживаются SunOS 4.1.1.
При использовании SNMP (рисунок 25.26) некоторые системы, как, например, Solaris 2.2, генерируют вывод netstat -s, который использует имена переменных SNMP.
Глава 7
- 86 байт поделенные на 960 байт/сек, умноженные на 2 дают 179,2 миллисекунды. Когда ping запущен с этой скоростью, печатаются значения равные 180 миллисекундам.
- (86 + 48) байт поделенные на 960 байт/сек, умноженные на 2 дают 279,2 миллисекунды. Появление дополнительных 48 байт объясняются тем, что последние 48 байт из 56 байт в части данных должны быть экранированы: 0xc0 это символ END в протоколе SLIP.
- CSLIP сжимает только TCP и IP заголовки в TCP сегментах. Он не влияет на ICMP сообщения, которые используются программой ping.
- На SPARCstation ELC ping на loopback адрес дает RTT равное 1,310 миллисекунды, тогда как ping на Ethernet адрес хоста дает RTT равное 1,460 милисекунды. Эта разница объясняется дополнительной обработкой, осуществляемой Ethernet драйвером, который определяет, что датаграмма действительно предназначена локальному хосту. Вам потребуется версия ping, которая дает микросекундное разрешение, чтобы оценить подобную разницу.
Глава 8
- Если входящая датаграмма имеет TTL равное 0, вычитание единицы и затем проверка могут установить TTL в значение 255 и продлить существование датаграммы. Несмотря на то, что маршрутизатор никогда не должен получать датаграммы с TTL равным 0, это может произойти.
- Мы заметили, что traceroute сохраняет 12 байт данных из раздела данных UDP датаграммы, которые содержат время отправки датаграммы. Однако, из рисунка 6.9 видно, что ICMP возвращает только первые 8 байт IP датаграммы, которая вызвала ошибку, там находилось 8 байт UDP заголовка. То есть, значение времени, сохраненное traceroute, не возвратилось в ICMP сообщение об ошибке. traceroute сохранила время, при отправке пакета, а когда был получен ICMP отклик, определила текущее время и, использовав эти два значения, получила RTT. Из главы 7 мы видим, что ping сохраняет время в исходящем ICMP эхо запросе, а сервер отражает эти данные. Это позволяет ping напечатать корректный RTT, даже если пакеты вернулись беспорядочно.
- Первая строка вывода корректна и указывает на R1. Следующая проба стартует с TTL равным 2, оно уменьшается на единицу в R1. Когда R2 получает датаграмму с уменьшенным на единицу TTL (от 1 до 0), то некорректно перенаправляет ее в R3. R3 видит, что входящий TTL равен 0 и отправляет назад ошибку об истечении времени. Это означает, что вторая строка вывода (для TTL равного 2) указывает на R3, а не на R2. Третья строка вывода корректно указывает на R3. Ошибка присутствует в двух последовательных строках вывода, которые указывают на один и тот же маршрутизатор.
- В данном случае TTL равное 1 указывает на R1, TTL равное 2 указывает на R2, а TTL равное 3 указывает на R3; однако, когда TTL равно 4, UDP датаграммы достигает пункта назначения со входящим TTL равным 1. Генерируется ICMP ошибка о недоступности порта, однако TTL сообщение об ошибке равно 1 (некорректно скопировано из входящего TTL). ICMP сообщение идет на R3, где TTL уменьшается на единицу, и сообщение отбрасывается. ICMP ошибка об истечении времени не генерируется, так как датаграмма, которая была отброшена, - это ICMP сообщение об ошибке (порт недоступен). Тоже происходит и с пробой, TTL которой равен 5, однако на этот раз исходящая ошибка о недоступности порта стартует с TTL равным 2 (скопировано из входящего TTL), и доходит до R2, где отбрасывается. Ошибка о недоступности порта, соответствующая пробе с TTL равным 6, доходит до R1, где тоже отбрасывается. И, в конце концов, ошибка о недоступности порта для пробы с TTL равным 7 проходит полный путь и возвращается назад с входящим TTL равным 1. (traceroute считает, что прибывающее ICMP сообщение с TTL равным 0 или 1 это одно и то же, поэтому она печатает восклицательный знак после RTT.) И в завершение, строки с TTL равными 1, 2 и 3 корректно идентифицируют R1, R2 и R3, затем следуют три строки, каждая из которых содержит три тайм-аута, за которым следует строка для TTL равного 7, которая идентифицирует пункт назначения.
- Все эти маршрутизаторы установили исходящий TTL ICMP сообщения в значение 255. Это общепринятая практика. Как мы и ожидали, входящее значение от netb равно 255, однако значение равное 253 от butch означает, что возможно где-то есть "невидимый" маршрутизатор. Иначе в этой точке появился бы входящий TTL равный 254. Точно так же, от enss142.UT.westnet.net мы ожидаем значение равное 252, а не 249. Это означает, что и здесь есть "невидимые" маршрутизаторы, которые некорректно обработали UDP датаграмму, однако они корректно уменьшили TTL и вернули ICMP сообщение.
Необходимо достаточно внимательно просматривать исходящий TTL, так как иногда значение отличается от ожидаемого. Это может объясняться тем, что ICMP сообщение возвращается по другому пути, нежели ушла исходящая UDP датаграмма. В этом примере, однако, существуют именно "невидимые" маршрутизаторы, которые traceroute не нашла при использовании опции свободной маршрутизации от источника.
Клиент traceroute устанавливает номер порта источника UDP в логическое ИЛИ со своим идентификатором процесса и 32768. Так как возвращенное ICMP сообщение всегда содержит первые 8 байт IP датаграммы, на которую сгенерирована ошибка (рисунок 6.9), что включает целиком UDP заголовок, этот номер порта источника возвращается в ICMP ошибке.
Клиент traceroute не может поступить подобным образом, потому что все, что возвращается в ICMP ошибке, - это UDP заголовок (рисунок 6.9), а не UDP данные. Таким образом, traceroute должна помнить, когда она посылает запрос, дождаться отклика и рассчитать разницу во времени.
Это иллюстрирует еще одно различие между Ping и Traceroute: Ping отправляет один пакет в секунду, вне зависимости от того, получены ли какие-либо отклики, тогда как Traceroute отправляет запрос и затем ожидает, придет ли отклик или будет отработан тайм-аут перед отправкой следующего запроса.
Глава 9
- Когда впервые был разработан стандарт ICMP, RFC 792 [Postel 1981b], разделение на подсети не использовалось. Также, использование перенаправления в одну сеть вместо перенаправления на N хостов (для всех N хостов, находящихся в сети назначения) сохраняет некоторое пространство в таблице маршрутизации.
- Эта запись не требуется, однако если она удалена, все IP датаграммы, предназначенные slip, посылаются на маршрутизатор по умолчанию (sun), который затем перенаправляет их на маршрутизатор bsdi. Так как sun перенаправляет датаграммы по тому же интерфейсу, по которому они были получены, он отправляет ICMP перенаправление хосту svr4. При этом создается та же самая запись в таблице маршрутизации хоста svr4, которая была удалена, однако в этот раз она создается путем перенаправления, вместо того чтобы создаваться в момент загрузки машины.
- Когда хост 4.2BSD получает датаграмму, предназначаемую для 140.1.255.255, он определяет, что у него есть маршрут к сети (140.1), поэтому он старается направить датаграмму. Чтобы сделать это, он посылает широковещательный запрос ARP в поисках 140.1.255.255. Так как на запрос не приходит отклик, датаграмма отбрасывается. Если на кабеле существует несколько хостов 4.2BSD, каждый отправляет этот ARP широковещательный запрос в одно и то же время, при этом сеть временно становится практически недоступной.
- В этом случае отклик приходит на каждый ARP запрос, где сообщается, что каждому хосту 4.2BSD необходимо послать датаграмму на указанный аппаратный адрес (широковещательный запрос Ethernet). Если существует k хостов 4.2BSD на этом кабеле, все получают свой собственный ARP отклик, в результате чего, каждый из них генерирует еще один широковещательный запрос. Каждый хост получает каждую широковещательную IP датаграмму, направляемую на 140.1.255.255, а так как каждый хост сейчас имеет запись в ARP кэше, датаграмма снова направляется на широковещательный адрес. Это продолжается и генерирует так называемое половодье Ethernet (meltdown). [Manber 1990] описывает другие формы цепных реакций в сетях.
Глава 10
- Тринадцать из этих маршрутов пришли от kpno: все, за исключением 140.252.101.0 и 140.252.104.0 - это сети, к которым gateway подключен непосредственно.
- Перед тем как 25 маршрутов, объявленных в потерянной датаграмме, будут обновлены пройдет шестьдесят секунд. В этом нет никакой проблемы, потому что RIP объявляет маршрут умершим только в том случае, если в течение 3-х минут не было обновлений.
- RIP работает поверх UDP, а UDP предоставляет необязательную контрольную сумму для данных, находящихся в UDP датаграмме (глава 11, раздел "Контрольная сумма UDP"). OSPF, однако, работает поверх IP. Контрольная сумма IP охватывает только IP заголовок, таким образом, OSPF должен добавлять свое собственное поле контрольной суммы.
- Балансировка загруженности уменьшает вероятность того, что пакеты будут доставлены в беспорядке, что может исказить времена возврата, рассчитанные транспортным уровнем.
- Это называется простым "расщепленным горизонтом" (технология расщепленных горизонтов основывается на том факте, что бессмысленно отправлять информацию о маршрутах в том направлении, откуда она пришла).
- На рисунке 12.1 мы показали, что каждый из ста хостов обрабатывает широковещательную UDP датаграмму через драйвер устройства, IP уровень и UDP уровень, где она будет окончательно отброшена, когда будет обнаружено, что UDP порт 520 не обслуживается.
Глава 11
- Так как при использовании инкапсуляции IEEE 802 в заголовке находится 8 дополнительных байт, 1465 байт пользовательских данных - это наименьший размер, который вызовет фрагментацию.
- Для IP посылается 8200 байт, 8192 байта пользовательских данных и 8 байт UDP заголовка. Используя форму записи tcpdump, первый фрагмент это 1480@+ (1480 байт данных, смещение 0 и установлен бит "дальше следуют еще фрагменты"). Второй это 1480@1480+, третий 1480@2960+, четвертый 1480@4440+, пятый 1480@5920+ и шестой 800@7400. 1480 x 5 + 800 = 8200 это количество байт, которые необходимо отправить.
- Каждый фрагмент размером 1480 байт поделен на три части: два фрагмента по 528 байт и один фрагмент 424 байта. Максимальное число кратное 8, меньшее чем 532 (552 - 20), это 528. Фрагмент размером 800 байт делится на две части: фрагмент размером 528 байт и фрагмент размером 272 байта. Таким образом, из исходной датаграммы размером 8192 байта получается 17 фреймов, которые передаются по SLIP каналу.
- Нет. Проблема заключается в том, что когда приложение осуществляет тайм-аут и повторную передачу, IP датаграмма, сгенерированная при повторной передаче, имеет новое поле идентификации. Промежуточная сборка осуществляется только для фрагментов, которые имеют одинаковое поле идентификации.
- Поле идентификации в IP заголовке одно и то же (47942).
- Во-первых, из рисунка 11.4 мы видим, что у gemini выключен расчет исходящей контрольной суммы UDP. Вполне возможно, что операционная система на этом хосте (SunOS 4.1.1) это одна из тех, что никогда не проверяют входящую контрольную сумму UDP, если не включен расчет исходящей контрольной суммы UDP. Во-вторых, вполне возможно, что большинство UDP траффика это локальный траффик, а не траффик по глобальным сетям. Поэтому нет необходимости исполнять все прихоти свойственные глобальным сетям.
- Опции свободной и жесткой маршрутизации от источника копируются в каждый фрагмент. Опция временной марки и опция записи маршрута не копируются в каждый фрагмент - они присутствуют только в первом фрагменте.
- Нет. Мы видели в разделе "Сервер UDP" главы 11, что большинство реализаций могут фильтровать входящие датаграммы, направляемые на заданный номер порта UDP, на основании IP адреса назначения, IP адреса источника и номера порта источника.
Глава 12
- Широковещательные запросы сами по себе не увеличивают сетевой траффик, однако они требуют дополнительной обработки на хостах. Широковещательные запросы могут вызвать увеличение сетевого траффика, если получающие хосты некорректно отвечают с помощью ошибок, таких как ICMP ошибки о недоступности порта. Маршрутизаторы обычно не перенаправляют широковещательные пакеты, однако их перенаправляют мосты, таким образом, широковещательные запросы в сетях, построенных на основе мостов, могут уйти значительно дальше, чем в сетях, построенных на маршрутизаторах.
- Каждый хост получает копию каждого широковещательного запроса. Интерфейсный уровень получает фрейм и передает его в драйвер устройства. Если поле типа принадлежит какому-либо другому протоколу, драйвер устройства отбрасывает фрейм.
- Сначала исполним netstat -r, чтобы посмотреть таблицу маршрутизации. Она покажет имена всех интерфейсов. Затем запустим ifconfig (глава 3, раздел "Команда ifconfig") для каждого интерфейса: флаги расскажут нам, поддерживает ли интерфейс широковещательные запросы, и если да, то в выводе также будут показаны широковещательные адреса.
- Berkeley реализации не позволяют фрагментировать широковещательные датаграммы. Когда мы указываем длину равную 1472 байта, результирующая IP датаграмма будет длиной ровно 1500 байт, что равно MTU Ethernet. Запрет на фрагментацию широковещательных датаграмм это политическое решение. Технической причины не существует (а именно, никакой другой причины, нежели просто уменьшить количество широковещательных пакетов).
- В зависимости от того, поддерживается ли групповая рассылка в различных сетевых платах Ethernet на 100 хостах, групповая датаграмма может быть игнорирована сетевой платой или отброшена драйвером устройства.
Глава 13
- Используйте некоторые уникальные значения для хоста при генерации случайных значений. IP адрес и адрес канального уровня это два значения, которые должны отличаться на каждом хосте. Время дня это плохой выбор, особенно если все хосты используют, например, протокол NTP для синхронизации своих часов.
- Они добавляют заголовок протокола приложения, который включает номер последовательности и временную марку.
Глава 14
- Разборщик - это всегда клиент, однако сервер имен это и клиент, и сервер.
- Возвращенный вопрос, он рассчитан для первых 44 байт. Единственный ответ занимает оставшийся 31 байт: 2-байтный указатель на имя домена (указатель на имя домена в вопросе), 10 байт на поля фиксированного размера (тип, класс, TTL и длина ресурса) и 19 байт для данных ресурса (имя домена). Обратите внимание, что имя домена в данных ресурса (svr4.tuc.noao.edu.) не делит суффикс с именем домена в вопросе (34.13.252.140.in-addr.arpa.), таким образом, указатель не может быть использован.
- Использование обратного порядка означает использование, во-первых, DNS, и затем, если это не сработает, попытку конвертировать аргумент в номер, состоящий из десятичных чисел, разделенных точками (форма записи IP адреса). Это означает, что каждый раз, когда используется адрес в виде десятичных цифр, разделенных точками, используется DNS, при этом привлекается DNS сервер. На это тратятся дополнительные ресурсы.
- Раздел 4.2.2 RFC 1035 указывает, что перед реальным DNS сообщением должна стоять 2-байтовая длина.
- Когда сервер имен стартует, он обычно читает (вполне возможно, устаревший) список корневых серверов из дискового файла. Затем он старается установить контакт с одним из этих корневых серверов, запрашивая записи сервера имен (тип запроса NS) для корневого домена. При этом возвращается текущий список корневых серверов. Минимум, что необходимо для этого, это чтобы хотя бы одна запись в стартовом файле на диске соответствовала текущему положению.
- Регистрационный сервер InterNIC обновляет корневые сервера три раза в неделю.
- Разборщик функционирует как приложение; если система сконфигурирована таким образом, чтобы использовать несколько DNS серверов, разборщик не может отслеживать времена возврата до различных DNS серверов. Это может привести к возникновению тайм-аутов на слишком короткие запросы разборщика, при этом будут происходить ненужные повторные передачи.
- Сортировка записей А должна осуществляться разборщиком, а не сервером имен, так как разборщик обычно знает больше, чем сервер, о топологии сети клиента. (Новые релизы BIND предоставляют разборщику возможность сортировать А записи.)
Глава 15
- TFTP запросы, посылаемые на широковещательный адрес, должны быть игнорированы. Как указывается в требованиях к хостам Host Requirements RFC, ответы на широковещательные запросы могут создать значительные проблемы в безопасности. Проблема, однако, заключается в том, что не все реализации и API предоставляют адрес назначения для UDP датаграмм для процессов, которые получают датаграммы (глава 11, раздел "Сервер UDP"). По этой причине многие TFTP серверы не следуют этому ограничению.
- К сожалению, RFC ничего не говорит о подобном переходе номера блоков. Реализации должны иметь возможность передавать файлы размером до 33553920 байт (65535 x 512). Большинство реализаций выдают ошибку, когда размер файла превышает 16776704 (32767 x 512), так как они некорректно определяют количество блоков в виде 16-битного целого со знаком, вместо того чтобы использовать целое без знака.
- Это упрощает реализацию TFTP клиента, что позволяет поместить его в ПЗУ, потому что сервер является отправителем загрузочных файлов, таким образом, сервер должен осуществлять тайм-ауты и повторные передачи.
- Так как TFTP - протокол с остановкой и ожиданием отклика, он может передавать максимум 512 байт за одну посылку от клиента серверу. Максимальная пропускная способность TFTP составляет в таком случае 512 байт, поделенных на время возврата между клиентом и сервером. В случае Ethernet (представим время возврата равное 3 миллисекундам), максимальная пропускная способность будет составлять примерно 170000 байт в секунду.
Глава 16
- Маршрутизатор должен перенаправлять RARP запросы на какой-либо другой хост, находящийся в другой сети, подключенной к маршрутизатору, однако отправка отклика может вызвать некоторые проблемы. Маршрутизатор также должен перенаправлять RARP отклики.
BOOTP не имеет этих проблем с откликами, так как адрес отклика это обычный IP адрес, причем маршрутизатор всегда знает, как перенаправить информацию на этот адрес. Проблема заключается в том, что RARP использует адреса только канального уровня, а маршрутизаторы обычно не знают этих значений для хостов, находящихся в других, не подключенных непосредственно, сетях.
Глава 17
- Все обязательные, за исключением UDP контрольной суммы. Контрольная сумма IP охватывает только IP заголовок, тогда как остальные захватывают все непосредственно после IP заголовка.
- IP адрес источника, номер порта источника или поле протокола должны быть повреждены.
- Большинство приложений Internet используют возврат каретки и пропуск строки, чтобы указать на конец каждой записи от приложения. Это кодирование NVT ASCII (глава 26, раздел "Протокол Telnet"). Альтернативным способом является установка префикса перед каждой записью, содержащего счетчик байтов, который используется в DNS (упражнение 4 главы 14) и Sun RPC (глава 29, раздел "Вызов удаленной процедуры Sun").
- Как мы видели в разделе "ICMP ошибка недоступности порта" главы 6, ICMP ошибка должна вернуть по крайней мере первые 8 байт, находящиеся позади IP заголовка в IP датаграмме, которая вызвала ошибку. Когда TCP получает ICMP ошибку, он должен проверить два номера порта, чтобы определить какому соединению соответствует ошибка, поэтому номер порта должен находиться в первых 8 байтах TCP заголовка.
- Существуют опции, находящиеся в конце TCP заголовка, однако в UDP заголовке не существует опций.
Глава 18
- ISN это 32-битный счетчик, который перескакивает со значения примерно 4294912000 на 8704, приблизительно через 9,5 часов после того, как система была загружена. По прошествию еще примерно 9,5 часов он перескакивает на 17408, затем на 26112 еще после 9,5 часов, и так далее. Так как ISN стартует с 1, когда система загружается, и так как минимальный порядок циклов цифр через 4, 8, 2, 6 и 0, ISN всегда должен быть нечетным числом.
- В первом случае мы использовали нашу программу sock, а она по умолчанию передает Unix символ новой строки так, как он есть - один ASCII символ 012 (восьмеричный). Во втором случае мы использовали Telnet клиента, а он конвертирует Unix символ новой строки в два ASCII символа - возврат каретки (восьмеричный 015), за которым следует пропуск строки (восьмеричный 012).
- В случае полузакрытого соединения один конец отправляет FIN и ожидает данные или FIN с удаленного конца. Полуоткрытое соединение это когда один конец вышел из строя, но это неизвестно удаленному концу.
- Соединение может войти в состояние ожидания 2MSL только в том случае, если оно уже было в состоянии ESTABLISHED.
- Во-первых, сервер дневного времени осуществляет активное закрытие TCP соединения после того, как он выдал дату и время клиенту. Это ясно из сообщения, напечатанного нашей программой sock: "connection closed by peer" (соединение закрыто удаленным концом). Клиент в этом соединении прошел через состояние пассивного закрытия. Это помещает пару сокетов в состояние TIME_WAIT на сервере, но не на клиенте. Затем, как показано на рисунке 18.6, большинство Berkeley реализаций позволяют прибыть новому запросу на соединение на пару сокетов, находящуюся в состоянии TIME_WAIT, это как раз то, что произошло в данном случае.
- Сброс посылается в ответ на FIN, потому что FIN прибывает для соединения, которое было в состоянии CLOSED.
- Сторона, которая набирает номер, осуществляет активное открытие. Сторона, на которой звонит телефон, осуществляет пассивное открытие. Одновременное открытие не разрешено, однако разрешено одновременное закрытие.
- Мы бы увидели только ARP запросы, а не TCP сегменты SYN, однако ARP запросы имеют то же временное расписание, как и на рисунке.
- Клиент это хост solaris, а сервер это хост bsdi. Подтверждение клиента (ACK) на SYN сервера комбинируется с первым сегментом данных от клиента (строка 3). Это полностью допустимо по правилам TCP, однако большинство реализаций так не поступают. Затем клиент посылает свой FIN (строка 4) не дождавшись ACK на свои данные. Это позволяет серверу подтвердить и данные, и FIN в строке 5. Этот обмен (отправка одного сегмента данных от клиента к серверу) требует 7 сегментов. Обычное установление и прекращение соединения (рисунок 18.13), вместе с одним сегментом данных и его подтверждением, требуют 9 сегментов.
- Во-первых, подтверждение сервера (ACK) на FIN клиента обычно не задерживается (мы обсуждаем задержанные ACK в разделе "Задержанные подтверждения" главы 19), а отправляется сразу же, по прибытию FIN. В этом случае, когда приложение получает EOF, оно сообщает своему TCP о необходимости закрыть свой конец соединения. Во-вторых, сервер, который получил FIN, не должен закрывать свой конец соединения по получении FIN от клиента. Как мы видели в разделе "Наполовину закрытый TCP" главы 18, данные все еще могут быть отправлены.
- Если прибывающий сегмент, на который сгенерирован RST, имеет поле ACK, номер последовательности RST берется из поле ACK прибывшего сегмента. Значение ACK равное 1 в строке 6 соответствует ISN равному 26368001 в строке 2.
- См. [Crowcroft et al. 1992] для получения комментариев о создании уровней.
- Выдается пять запросов. Представьте, что три пакета используются для установления соединения, один для запроса, один для подтверждения (ACK) запроса, один для отклика, один для ACK на отклик и четыре для того, чтобы закрыть соединение. Это означает, что используется 11 пакетов на один запрос, то есть всего 55 пакетов. При использовании UDP это значение уменьшается до 10 пакетов.
Оно может быть уменьшено до 10 пакетов на запрос, если ACK на запрос комбинируется с откликом (глава 19, раздел "Задержанные подтверждения").
Глава 19
- Две записи приложения, за которыми следует чтение, вызывают задержку, потому что, скорее всего, используется алгоритм Нагла. Первый сегмент (с 8 байтами данных) отправляется, на него ожидается ACK перед отправкой 12 байт данных. Если сервер поддерживает задержанные ACK, он может осуществить задержку до 200 миллисекунд (плюс RTT), перед тем как этот ACK будет получен.
- В случае 5-байтовых CSLIP заголовков (IP и TCP) и 2-х байт данных, RTT по SLIP каналу для этих сегментов составит примерно 14,5 миллисекунды. Это RTT по Ethernet (обычно 5-10 миллисекунд), к которому необходимо добавить время маршрутизации на sun и bsdi. Таким образом, приведенное время выглядит вполне правдоподобно.
- На рисунке 19.6 разница во времени между сегментами 6 и 9 составляет примерно 533 миллисекунды. На рисунке 19.8 разница во времени между сегментами 8 и 12 составляет 272 миллисекунды. (Мы рассчитали время для клавиши F2, а не для клавиши F1, так как первое эхо для клавиши F1 на втором рисунке было потеряно.)
Глава 20
- Байт с номером 0 это SYN, а байт с номером 8193 это FIN. SYN и FIN занимают по одному байту в пространстве номеров последовательности.
- Первая запись, которую осуществляет приложение, вызывает отправку первого сегмента с флагом PUSH. Так как BSD/386 всегда использует медленный старт, она ожидает первый ACK перед отправкой остальных данных. В течение этого времени приложение осуществляет следующие три записи, в это же время в TCP буферы записываются данные, которые необходимо отправить. Следующие три сегмента не содержат флага PUSH, так как в буфере данных достаточно для отправки. Здесь к записям приложения начинается применяться медленный старт, при этом каждая запись приложения вызывает отправку сегмента, а так как этот сегмент является последним в буфере, устанавливается флаг PUSH.
- Необходимо определить емкость, для чего надо решить уравнения ширины пропускания в зависимости от задержки. Результаты будут следующими: 1920 байт в первом случае и 2062 для спутникового канала. Похоже, принимающий TCP объявляет окно равное всего лишь 2048 байт.
Насытить спутниковый канал можно при использовании окна большего, чем 16000 байт.
Глава 21
- Следующий тайм-аут устанавливается в 48 секунд: 0 + 4 x 12. Коэффициент равный 4 это следующий множитель при экспотенциальном наращивании.
- Похоже, что SVR4 все еще использует коэффициент 2D вместо 4D при расчете RTO.
- Протокол с остановкой и ожиданием подтверждения, который используется в TFTP, ограничен отправкой 512 байт данных за время возврата. 32768/512 x 1,5 это 96 секунд.
- Показано четыре сегмента, пронумерованные как 1, 2, 3 и 4. Представьте, что они приняты в следующем порядке: 1, 3, 2 и 4. Подтверждения, сгенерированные получателем, будут ACK 1 (нормальный ACK), ACK 1 (дублированный ACK, когда принят сегмент 3, который пришел не в свое время), ACK 3, когда принят сегмент 2 (подтверждающий оба сегмента 2 и 3), и затем ACK 4. В этом случае сгенерирован один дублированный ACK. Если порядок приема будет 1, 3, 4, 2, то будет сгенерировано два дублированных ACK.
- Нет, потому что наклон все еще вправо-вверх, а не вниз.
- См. рисунок E.1.
- На рисунке 21.2 сегменты содержат 256 байт данных, передача по по CSLIP каналу со скоростью 9600 бит/сек между slip и bsdi, занимает примерно 250 миллисекунд. Представим, что сегменты данных не были поставлены в очередь где-нибудь между bsdi и vangogh, они прибыли на vangogh примерно через 250 миллисекунд. Так как это больше чем 200 миллисекунд (величина таймера задержанного ACK), каждый сегмент подтверждается, когда истекает следующий таймер задержанного ACK.
Глава 22
- Подтверждения (ACK), возможно, все задержаны на хосте bsdi, потому что нет необходимости посылать их немедленно. Именно поэтому соответственные времена имеют 0,170 и 0,370 в дробной части. Также, похоже на то, что 200-миллисекундный таймер на bsdi запущен примерно на 18 миллисекунд позже, чем тот же самый таймер на sun.
- Флаг FIN, так же как флаг SYN, занимает 1 байт в пространстве номеров последовательности. Объявленное окно будет на 1 байт меньше, потому что TCP предоставляет место для 1 байта номера последовательности занятого флагом FIN.
Глава 23
- Обычно легче активизировать опцию "оставайся в живых", нежели пробы из приложения; пробы "оставайся в живых" требуют меньшей ширины пропускания сети, нежели пробы приложения (так как пробы "оставайся в живых" и ответы не содержат данных); пробы не посылаются, если соединение используется для передачи.
- Опция "оставайся в живых" может привести к тому, что абсолютно нормальное соединение будет разорвано, потому что сеть временно вышла из строя; интервал между пробами (2 часа) обычно не конфигурируется с точки зрения приложений;
Глава 24
- Это означает, что отправляющий TCP поддерживает опцию масштабирования окна, однако не нуждается в том, чтобы масштабировать свое окно для этого соединения. Удаленная сторона (которая получила этот SYN) может затем установить коэффициент масштабирования окна (который может быть равен 0 или нет).
- 64000: размер принимающего буфера (128000) сдвигается вправо на 1 бит. 55000: размер принимающего буфера (220000) сдвигается вправо на 2 бита.
- Нет. Проблема заключается в том, что подтверждения доставляются ненадежно (за исключением тех случаев, когда они двигаются вместе с данными), поэтому изменение шкалы, находящееся в ACK, может быть потеряно.
- 232 x 8 / 120 равно 286 Мбит/сек, что в 2,86 раза больше чем скорость данных FDDI.
- Каждый TCP должен помнить последнюю временную марку, полученную по любому соединению от каждого хоста. Прочитайте приложение B.2 в RFC 1323 для получения более подробной информации.
- Приложение должно установить размер принимающего буфера перед установлением соединения с удаленным концом, так как опция масштабирования окна посылается в исходном SYN сегменте.
- Если получатель подтверждает каждый второй сегмент данных, пропускная способность составляет 1118881 байт в секунду. При использовании окна размером 62 сегмента, с подтверждением каждого 31 сегмента, значение составляет 1158675.
- Когда опция временной марки отражается эхом в ACK, она всегда берется из сегмента, который подтверждается. В данном случае нет никакой двусмысленности по поводу того, какому повторно переданному сегменту принадлежит ACK, однако другая часть алгоритма Karnа, имеющая отношение к экспотенциальному наращиванию передачи, все еще требуется.
- Получающий TCP ставит данные в очередь, однако они не могут быть переданы приложению до тех пор, пока не завершится трехразовое рукопожатие: когда получающий TCP переходит в состояние ESTABLISHED.
- Осуществляется обмен пятью сегментами:
- От клиента к серверу: SYN, данные (запрос) и FIN. Сервер должен поставить в очередь данные, как описано в предыдущем упражнении.
- От сервера к клиенту: SYN и ACK на SYN клиента.
- От клиента к серверу: ACK на SYN сервера и FIN клиента (снова). Это приводит к тому, что сервер переходит в состояние ESTABLISHED, а данные, поставленные в очередь с сегмента 1, передаются приложению сервера.
- От сервера к клиенту: ACK на FIN клиента (который также подтверждает данные клиента), данные (отклик сервера) и FIN сервера. Здесь подразумевается, что SPT достаточно короток, чтобы позволить этот задержанный ACK. Когда TCP клиент получает этот сегмент, отклик передается приложению клиента, однако полное время будет равно удвоенному RTT плюс SPT.
- От клиента к серверу: ACK на FIN сервера.
Глава 25
- Если система запускает и менеджера, и агента, это скорее всего разные процессы. Менеджер слушает UDP порт 162 на предмет прихода ловушек, а агент слушает UDP порт 161 для запросов. Если один и тот же порт используется и для ловушек, и для запросов, отделить менеджера от агента будет достаточно сложно.
- Обратитесь к разделу "Таблица доступа" в разделе "Простые примеры" главы 25.
Глава 26
- Мы ожидаем, что сегменты 2, 4 и 9 от сервера будут задержаны. Разница во времени между сегментами 2 и 4 составляет 190,7 миллисекунды, а разница во времени между сегментами 2 и 9 составляет 400,7 миллисекунды.
Все ACK от клиента к серверу будут задержаны: сегменты 6, 11, 13, 15, 17 и 19. Разница во времени последних пяти от сегмента 6 составляет 400,0; 600,0; 800,0; 1000,0 и 2600 миллисекунд.
Ограничение TCP заключается в том, что пара сокетов, выделенная для соединения, должна быть уникальной. Так как Rlogin сервер всегда использует один и тот же заранее известный порт (513), несколько Rlogin клиентов на данном хосте могут использовать один и тот же зарезервированный порт, только если они подсоединены к различным серверам. Клиенты Rlogin, однако, не используют эту технику повторного использования зарезервированных портов. Если эта техника используется, теоретический лимит максимального количества соединений составляет 512 Rlogin клиентов, в одно и то же время подсоединенных к одному и тому же хосту сервера.
Глава 27
- Теоретически соединение не может быть установлено, пока пара сокетов находится в состоянии ожидания 2MSL на каком-либо из концов. В действительности, однако, мы видели в разделе "Диаграмма состояний передачи TCP" главы 18, что большинство Berkeley реализаций принимают все-таки новый SYN для соединения, находящегося в состоянии TIME_WAIT.
- Эти строки не являются частью отклика сервера, который всегда начинается с 3-циферного кода отклика.
Глава 28
- domain literal это IP адрес в виде десятичных цифр, разделенных точками, внутри квадратных скобок. Например: mail rstevens@ [140.252.1.54].
- Шесть: команда HELO, MAIL, RCPT, DATA, тело сообщения и QUIT.
- Это вполне законно и называется pipelining [Rose 1993, Sec. 4.4.4]. К сожалению, существуют "сумасшедшие" реализации SMTP, которые очищают свой входной буфер после обработки каждой команды, из-за чего подобная техника не работает. Если эта техника используется, клиент не может отбросить сообщение до тех пор, пока все отклики не будут проверены на предмет того, что сообщение было принято сервером.
- Рассмотрим первые пять сетевых обменов из упражнения 28.2. Каждый является маленькой командой (возможно, одним сегментом), который совсем немножко загружает сеть. Если все пять пройдут на сервер без повторных передач, окно переполнения должно быть равно шести сегментам, когда отправляется тело. Если тело большое, клиент может послать первые шесть сегментов за раз, что сеть, может быть, не сможет обработать.
- Новые реализации BIND смешивают MX записи с тем же самым значением, что и форма балансировки загрузки.
Глава 29
- Нет, потому что tcpdump не может отличить RPC запрос или отклик от любой другой UDP датаграммы. Единственное случай, когда интерпретируется содержание UDP датаграммы как NFS пакет, это когда номер порта источника или назначения равен 2049. Случайные RPC запросы и отклики могут использовать номер динамически назначаемого порта на каждом конце.
- Из раздела "Номера портов" главы 1 известно, что процесс должен иметь привилегии суперпользователя, чтобы назначить самому себе номер порта меньше чем 1024 (заранее известный порт). Несмотря на то, что это нормально для серверов, запускаемых системой, таких как Telnet сервер, FTP сервер и Port Mapper сервер, нет необходимости использовать это ограничение для всех RPC серверов.
- Две концепции, заложенные в этом примере, заключаются в том, что клиент игнорирует любые отклики от сервера, которые не имеют XID, ожидаемые клиентом, а UDP ставит в очередь полученные датаграммы (до определенного предела) до тех пор, пока приложение считывает эти датаграммы. XID не изменяются при тайм-аутах и повторных передачах, они изменяются только когда вызывается еще одна процедура сервера.
События, осуществляемые stubом клиента, следующие: момент времени 0: отправка запроса 1; момент времени 4: тайм-аут и повторная передача запроса 1; момент времени 5: получение отклика 1 от сервера, возвращение отклика приложению; момент времени 5: отправка запроса 2; момент времени 9: тайм-аут и повторная передача запроса 2; момент времени 10: получение отклика 1 от сервера, однако он игнорируется, так как мы ожидаем отклик 2; момент времени 11: получение отклика 2 от сервера, возвращение отклика приложению.
События на сервере следующие: момент времени 0: получение запроса 1, начало операции; момент времени 5: отправка отклика 1; момент времени 5: получение запроса 1 (от повторной передачи клиента в момент времени 4), начало операции; момент времени 10: отправка отклика 1; момент времени 10: получение запроса 2 (от передачи клиента в момент времени 5), начало операции; момент времени 11: отправка отклика 2; момент времени 11: получение запроса 2 (от повторной передачи клиента в момент времени 9), начало операции; момент времени 12: отправка отклика 2. Этот последний отклик сервера просто поставлен клиентским UDP в очередь для следующего приема, осуществляемого клиентом. Когда клиент считывает его, XID будет неверен, и клиент его проигнорирует.
Подобное, когда сервер выходит из строя и перезагружается, а приложение RPC сервера получает новый динамически назначаемый порт, может возникнуть с любым RPC приложением, которое не использует заранее известный порт.
Глава 30
- Напечатайте whois "net 88". Идентификаторы сети класса А 64-95 зарезервированы.
- Напечатайте whois whitehouse-dom. И команда host, и nslookup могут запросить DNS.
- Нет, xscope можно запустить на другом хосте (не на сервере). Если хосты разные, xscope может использовать TCP порт 6000 для входящих соединений.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную